Abstract
In this paper, we address the challenge of reconstructing general articulated 3D objects from a single video. Existing works employing dynamic neural radiance fields have advanced the modeling of articulated objects like humans and animals from videos, but face challenges with piece-wise rigid general articulated objects due to limitations in their deformation models.
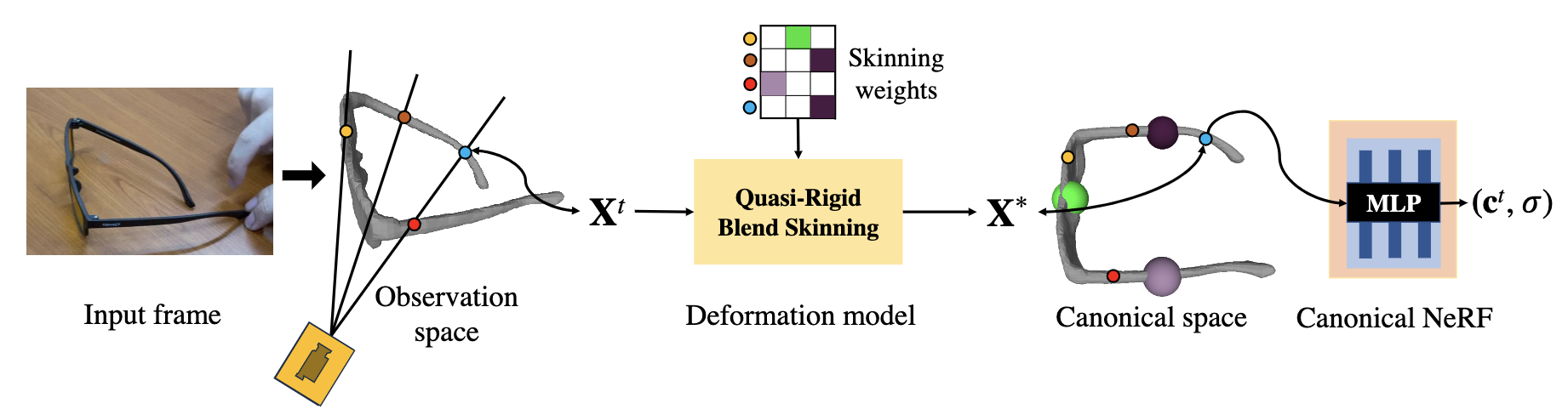
To tackle this, we propose Quasi-Rigid Blend Skinning, a novel deformation model that enhances the rigidity of each part while maintaining flexible deformation of the joints. Our primary insight combines three distinct approaches: 1) an enhanced bone rigging system for improved component modeling, 2) the use of quasi-sparse skinning weights to boost part rigidity and reconstruction fidelity, and 3) the application of geodesic point assignment for precise motion and seamless deformation. Our method outperforms previous works in producing higher-fidelity 3D reconstructions of general articulated objects, as demonstrated on both real and synthetic datasets.
Video
Poster